Введение
Реклама присутствует во всех телевизионных трансляциях и составляет значительную часть доходов телекомпаний. Последние решают множество технических задач по доставке контента от клиента до конечного потребителя. Одной из услуг, предоставляемой телевизионными компаниями, является врезка рекламы в трансляцию или, например, врезка таргетированной рекламы в видео заказчика [1]. Для того, чтобы вставить рекламный ролик в контент заказчика, необходимо знать метки времени вставки. В трансляциях без автоматической разметки меток работу по определению меток проводят люди, что является неэффективным и дорогим использованием человеческих ресурсов. Поэтому для решения задачи врезки рекламы в поток клиента необходим алгоритм детектирования рекламы в видеопотоке.
В данной работе проводится анализ существующих методов обнаружения рекламы в видеопотоке.
Поиск черных и бесшумных кадров
Темный или «черный» кадр видео может быть распознан путем изучения гистограммы яркости кадра, где большая часть «мощности» находится в нижней части амплитудного спектра пикселя. Таким образом, путем сравнения среднего значения яркости пикселя, представляющего весь кадр, с некоторым заданным порогом, может быть принято решение о том, можно ли считать этот кадр «черным» или нет. Кроме того, снижение громкости звука для конкретного видеокадра может быть распознано следующим образом: суммирование абсолютного значения всех аудиосэмплов, соответствующих одному видеокадру, может быть определено как «уровень звука» для этого кадра и для относительно тихих кадров можно ожидать низкий уровень звука. Таким образом, путем сравнения этого уровня звука с некоторым порогом могут быть обнаружены бесшумные кадры [2].
Возникновение одновременных черных кадров и затуханий звука может указывать на существование рекламной паузы. Тем не менее, возможно, что черные тихие кадры будут появляться во время самой программы. Например, они нередки, когда новостные программы переходят от ведущего к новостным сообщениям или во время смены сцен в сериалах. Для борьбы с этой проблемой и ее последствиями корректного обнаружения рекламной вставки можно учитывать, например, некоторые строгие условия. К таким условиям можно отнести количество подряд идущих черных тихих кадров. Также в качестве условия можно использовать длину рекламы.
К достоинствам такого подхода можно отнести простоту обнаружения, но такой метод не может стабильно точно определять рекламные паузы. Кроме того, чёрные кадры между рекламой могут быть заменены на заставку канала и возможны эпизоды в телепередачах, где часто встречаются чёрные кадры при смене сцен, никак не относящихся к рекламным.
Выделение характеристик из видеопотока
При использовании данного подхода видеопоток разделяется на фрагменты по смене сцен. Для каждого фрагмента вычисляются характеристики видео и звука, на основе которых определяется, относится фрагмент к рекламе или телепередаче [3].
Алгоритм выделения особенностей состоит из следующих шагов:
- разбиение на сцены и расчёт характеристик для каждой из них;
- классификация сцен по их характеристикам;
- пост-обработка.
Возможные выделяемые характеристики: среднее соотношение изменения краёв объектов (A-ECR); вариация соотношения изменения краёв объектов (V-ECR); средняя межкадровая разница (A-FD); вариация межкадровой разницы (V-FD); частота появления чёрных кадров (BFR); частота смены сцены (SF); определение типа звука (фоновый звук, музыка, речь, тишина).
Зависимость значений приведенных выше характеристик от типа телевизионного контента (обычная телепередача или рекламный блок) представлена на рисунке 1.
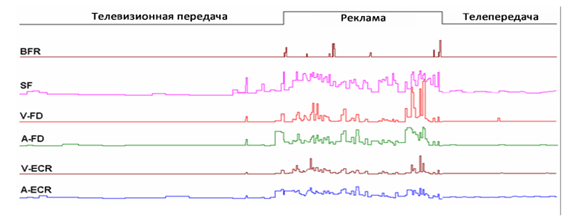
Рисунок 1. Зависимость характеристик от типа телевизионного контента
Пост-обработка после классификации видеопотока заключается в объединении слишком коротких блоков с соседями и перепроверке слишком длинных рекламные блоков.
Обнаружение повторяющихся рекламных блоков
Нередко реклама появляется более одного раза в течение видеотрансляции. Следовательно, мы можем обнаружить такие рекламные блоки, если запоминать их повторения.
Допустим, что частота кадров в секунду для видеопотока равна 25 fps. Хотя существуют видеопотоки с различной частотой кадров, это не повлияет на основную идею алгоритма. Всего за 3 часа трансляции количество кадров становится равным 25 * 60 * 60 * 3 = 270 000. Поиск двух похожих кадров «методом грубой силы» обойдется в 73 000 000 000 сравнений кадров, что совершенно недопустимо. Чтобы уменьшить количество вычислений, можно хэшировать каждый кадр в хеш-таблицу. Схема хэширования кадров изображена на рисунке 2.
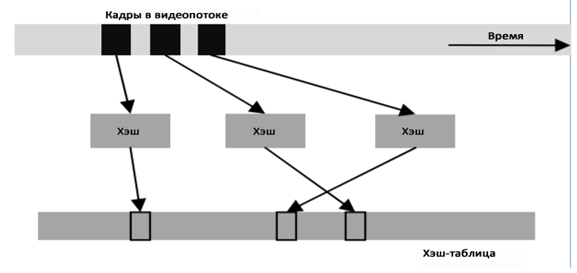
Рисунок 2. Схема хэширования кадров в видеопотоке
Хэш-значение для одного кадра можно получать следующим образом: выбираются N разных областей (окон) с фиксированными позициями и размерами и для каждой области вычисляется уровень серого.
Так как схожие кадры могут иметь одинаковое значение хеш-функции, это не гарантирует, что любые два кадра в одном и том же слоте хэша будут одинаковыми. Значение хэша может только уменьшить вычислительную сложность. То, насколько можно улучшить производительность алгоритма хэширования кадров, полностью зависит от того, насколько подходящая хэш-функция выбрана. Наилучшая хэш-функция должна равномерно распределять все кадры в разные хэш-значения [4].
Проверка совпадения видеоряда состоит в разделении кадра в момент времени t на подблоки. Чем больше подблоков выделяется, тем выше точность сравнения изображений, но и тем больше требуется вычислительного времени и места на диске. В результате рассчитываются средние RGB значения для каждого подблока и по ним сравниваются кадры, имеющие одинаковые хэш-значения.
Обнаружение неповторяющихся рекламных блоков
Рекламные объявления, которые не повторяются, намного труднее обнаружить. Если просто игнорировать такие рекламные блоки, то точность результатов резко упадет. Для того, чтобы обнаружить такой тип рекламы, можно, например, использовать знания о том, что каждая рекламная вставка в видеопотоке длится N минут, и все они являются рекламой. Более того, если две рекламы были обнаружены с использованием предыдущих методов поиска повторения и, если эти две рекламы показаны в течение N минутного интервала времени, можно сделать вывод, что все видеокадры между этими двумя рекламными объявлениями также должны принадлежать рекламной части [4]. Пример подобного обнаружения неповторяющихся рекламных блоков приведен на рисунке 3.

Рисунок 3. Пример обнаружения неповторяющихся рекламных блоков
Данный подход может быть интересен в масштабах телекомпаний, поскольку требует больших вычислительных мощностей. К его достоинствам можно отнести распознавание анонсов телепередач.
Поиск расположения текста в кадре
В большинстве случаев рекламные ролики содержат наложенные тексты, чтобы указывать на важную информацию. Характеристики наложенного текста в коммерческом сегменте отличаются от характеристик других типов программ [5]. Например, в качестве такой текстовой информации могут выступать названия компаний/брендов, которые очень часто упоминаются в рекламных вставках. Кроме того, зачастую в рекламе указываются условия акций, необходимый с законодательной точки зрения текст и подобная информация.
Поиск расположения логотипа в кадре
Телеканалы маркируют свои передачи логотипом в углу экрана. Во время рекламного блока логотип обычно исчезает. Таким образом, отслеживая наличие/отсутствие логотипа телеканала можно обнаруживать рекламные блоки [6].
Один из способов проверки наличия логотипа основан на идее, что в области логотипа значения цвета пикселя не меняются (непрозрачный логотип) или меняются в ограниченном диапазоне (полупрозрачный).
Перед выделением краёв объектов нужно удалить чёрные полосы с краёв изображения, иначе значение края на границе изображения и чёрной полосы может быть значительно выше значения края логотипа, и край логотипа будет отсечён по порогу бинаризации. Но данный критерий работает не для всех телеканалов и рекламных вставок.
Заключение
В ходе данной работы проведено исследование существующих методов обнаружения рекламы в видеопотоке. Рассмотрены различные используемые подходы для классификации части видеопотока как рекламного блока. Описаны ситуации, в которых предпочтительно использовать данные подходы, приведены их достоинства и недостатки, что соответствует техническому заданию.
Рассмотрен такой подход как поиск черных и бесшумных кадров. Проанализирована возможность извлечения характеристик из видеопотока, приведены возможные характеристики. Рассмотрен метод, основанный на поиске повторяющихся фрагментов и освещена проблема обнаружения неповторяющихся рекламных блоков и пути её решения. Проанализирована возможность классификации рекламных блоков на основании результатов поиска расположения текста и логотипа телеканала в кадре.
Использованные источники
- Malthouse E. C., Maslowska E., Franks J. The Role of Big Data in Programmatic TV Advertising //Advances in Advertising Research IX. – Springer Gabler, Wiesbaden, 2018. – С. 29-42.
- Kim Y. P., Kim K. H. Method for Detecting Start/End Time of TV Program on Web TV: By Detecting Black Level on Screen //The Journal of the Korea Contents Association. – 2015. – Т. 15. – №. 1. – С. 1-8.
- Vojvoda J., Beran V. Feature extraction for efficient image and video segmentation //Proceedings of the 32nd Spring Conference on Computer Graphics. – ACM, 2016. – С. 75-80.
- Baraldi L., Grana C., Cucchiara R. Shot and scene detection via hierarchical clustering for re-using broadcast video //International Conference on Computer Analysis of Images and Patterns. – Springer, Cham, 2015. – С. 801-811.
- Kun L. Application of the TV logo detection based on deep learning in network public opinion supervision //Wireless Internet Technology. – 2018. – №. 15. – С. 17.
- Kumar P., Puttaswamy P. S. Moving text line detection and extraction in TV video frames //2015 IEEE International Advance Computing Conference (IACC). – IEEE, 2015. – С. 24-28.
и
