В настоящее время, важной
проблемой на стыке математики и компьютерных наук является задача формализации
и обработки нечетких данных. Примером такой задачи, является задача распределения
работ по обслуживанию платежных терминалов с использованием экспертных оценок.
Одним из основных методов
распределения работ является метод динамического планирования. В динамическом
планировании используется подход классической архитектуры производства,
подразумевающий, что система представляет собой объединение секторов
обслуживания по территориальному признаку, которые контролируют разные
специалисты. Рассматриваемый подход заключается в том, что в начале периода
управления строится статистическое распределение работ с использованием методов
классической теории расписаний. После того, как обслуживание запускается в
соответствие с построенным таким образом расписанием, возможно возникновение
непредвиденных ситуаций, нарушающих стабильный процесс. В этих случаях
расписание корректируется таким образом, чтобы наиболее оптимальным образом
учесть нарушения.
Другим методом является
метод назначения работ в режиме реального времени, в котором каждый акт
технического обслуживания представляет собой производственный цикл, начиная от
планового обслуживания до обработки нештатных ситуаций, и таким образом, назначение
работ в режиме реального времени заключается в назначении набора операций
(работ) группе специалистов по прибытии заявки в систему мониторинга. В случае
нарушения выполнения какой-либо работы, ранее запланированные незавершенные
работы перераспределяются в порядке убывания уровня важности. Цель данного
подхода заключается в перераспределении операций в режиме реального времени.
Распределение может
производиться следующим образом:
1. Разбиваем
специалистов в рамках территориального распределения на группы 1, 2, 3 и т.д.
Каждый специалист может быть в одной или нескольких группах.
2. К каждой
группе применяем фильтр на заявки. Например, в группу 1 могут попасть только
заявки с набором требований N, а в группу 2 — N2. При этом фильтры могут
пересекаться.
3. Группы
выстраиваются в очередь. Вначале — та, которая дольше не была задействована в
обслуживании заявок. Если заявка попала в группу, то конкретный специалист из
группы назначается просто по очереди. Опять же, когда он принял заявку, то
попадает в конец (уже в этой группе). Если специалист присутствует в разных
группах, то он продвигается по очереди в них независимо. Это позволяет
распределять специалистов по их уровню. Нельзя слабых специалистов отправлять
на сложные технические работы. Такая система дает хорошую равномерность
распределения, а так же оставляет простор для ротации персонала между группами.
Как можно
заметить, группировка специалистов должна производиться по двум признакам:
1.
территориальный;
2.
профессиональный.
Очевидно, что
распределение по территориям возможна без применения эвристик, в виду того, что
имеются четкие критерии. В случае же распределения по профессиональному уровню
приходится иметь дело со сложно формализуемыми оценками.
Представим
вариант решения данной задачи с применением аппарата нечеткой логики [2].
Для оценки
уровня специалиста, введем лингвистическую переменную p. Универсальным множеством для
переменной p, является отрезок [0,1], а
множеством значений – терм-множество P= {P1, P2, P3, P4}, где:
1. P1 – «низкий уровень»;
2. P2 – «средний уровень»;
3. P3 – «высокий уровень»;
4. P4 – «очень высокий уровень»;
Каждый
терм из множества P является
именем нечеткого подмножества на отрезке [0,1]. Функции принадлежности каждого
подмножества представлены ниже в таблице 1. Следует отметить, что значения
выбираются так, чтобы диапазон значений уменьшался с повышением уровня
лингвистической оценки. Впоследствии эти значения могут корректироваться.
|
Терм Pk |
Функция принадлежности нечеткого множества Pk |
|
P1 – «низкий
|
|
|
P2 – «средний
|
|
|
P3 – «высокий
|
|
|
P4 – «очень
|
|
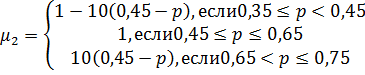
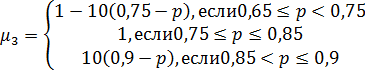
Таблица 1. Функции принадлежности
нечеткого множества P
Значение
функции принадлежности считается мерой истинности терма Pk, в
зависимости от значения оценки специалиста. Оценка специалиста производится на
основе его характеристик, при этом выбираются такие, рост которых приводит к
росту уровня специалиста. В представленном примере были определены следующие
показатели оценки:
1.![]() – продуктивность
– продуктивность
изменяется от 0 до 800;
2. ![]() – средняя скорость
– средняя скорость
выполнения изменяется от 0 до 1;
3. ![]() – средняя скорость
– средняя скорость
ответа на заявку изменяется от 0 до 5;
4. ![]() –
–
точность исполнения изменяется от 0 до 1;
Следует
отметить, что диапазон изменения параметров устанавливается экспертом и
впоследствии может меняться. Для того, чтобы ранжировать каждый показатель по
уровням пригодности, представим его как числовую переменную, т.е. переменную,
принимающую значения на определенном промежутке. Каждая из этих переменных
является множеством носителей лингвистических переменных, состоящих из
следующих термов:
1. ![]() – «низкий уровень
– «низкий уровень
показателя»;
2. ![]() – «средний уровень
– «средний уровень
показателя»;
3. ![]() – «высокий уровень
– «высокий уровень
показателя»;
4. ![]() – «лучший уровень
– «лучший уровень
показателя».
Для
каждой переменной определена трапециевидная функция принадлежности:
|
|
(1) |

Функцию
можно определить, как набор из четырех чисел:
![]() ,
,
где с помощью параметров определяются диапазоны уровней каждого признака.
Оценки всех термов ![]() представлены
представлены
в таблице 2.
|
Показатель |
Терм |
|||
|
|
|
|
|
|
|
|
(0,0,100,200) |
(100,200,300,400) |
(300,400,500,600) |
(500,600,800,800) |
|
|
(0;0;0,1;0,15) |
(0,1;0,15;0,25;0,35) |
(0,25;0,35;0,50;0,75) |
(50;0,75;1;1) |
|
|
(0;0;1;1,5) |
(1;1,5;2;3) |
(2;3;3,5;4) |
(3,5;4;5;5) |
|
|
(0;0;0,1;0,15) |
(0,1;0,15;0,25;0,35) |
(0,25;0,35;0,50;0,75) |
(50;0,75;1;1) |
Таблица 2. Оценки признаков по каждому
показателю
Для
перехода от значений характеристик специалистов
![]() к
к
высказываниям об уровне специалиста
![]() ,
,
необходимо взвесить каждый признак по уровню вклада. В данном примере принято,
что показатели вносят равный вклад, что можно выразить следующим образом:
|
|
(2) |
где ![]() – уровень
– уровень
вклада каждого признака, n – число
признаков.
При
данной системе показателей переход от показателей к весам термов
лингвистической переменной g, будет
иметь вид суммы всех функций принадлежности уровня показателей:
|
|
(3) |
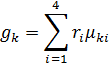
где ![]() –
–
вес k-ого терма лингвистической переменной P.
После
вычисления веса каждого терма лингвистической переменной, можно получить
значение самой лингвистической переменной p по формуле:
|
|
(4) |

где ![]() –
–
середина промежутка, который является носителем терма
![]() .
.
В
общем виде схема перехода от показателей к лингвистическим оценкам пригодности
показана на рисунке 1.

Рисунок 1.
Схема перехода от оценок к уровню пригодности.
Как
можно заметить, при вычислении итогового результата производится суммирование
оценок по каждому признаку, поэтому низким оценкам показателей, ставятся в
соответствие низкие значения уровня специалистов.
Для
примера работы модели взяты характеристики трех специалистов, представленных в
таблице 3.
|
Номер |
средняя скорость выполнения |
средняя скорость ответа |
средняя скорость ответа |
точность исполнения |
|
1 |
733 |
0,8 |
4,5 |
0,85 |
|
2 |
320 |
0,28 |
2 |
0,3 |
|
3 |
123 |
0,1 |
1 |
0,1 |
Таблица 3. Примерные характеристики
Ниже представлен пример
расчета оценки для №1 (см. табл. 3)
1. Расчет весов
термов лингвистической переменной P (3):
![]()
2. Нахождение суммы
весов: ![]()
3. Вычисление
значения лингвистической переменной(4):
![]()
4. Определение оценки
специалиста: ![]() P4
P4
– «лучший
уровень»;
Применяя
аналогичные действия при исходных данных, получаем результаты, представленные в
таблице 4.
|
№ |
Средняя скорость выполнения |
Средняя скорость ответа |
Средняя скорость ответа |
Точность исполнения |
Уровень |
|
1 |
Очень высокий |
Очень высокий |
Очень высокий |
Очень высокий |
Лучший |
|
2 |
Средний |
Средний |
Средний |
Средний |
Средний |
|
3 |
Низкий |
Низкий |
Низкий |
Низкий |
Низкий |
Таблица 4.
Результаты оценки
Далее
после проведения оценки может производиться формирование групп, например, по
принципу «лучшие с лучшим» или подвергнуть дополнительным методам оценки, если
необходимо. В качестве вывода можно отметить следующие моменты:
1. Данная
модель легко расширяется при добавлении в оценку дополнительных показателей;
2. Уровни
оценки, как характеристик, так и непосредственно уровня специалиста, легко
подвергаются масштабированию;
3. За
счет выбора функций принадлежности можно настраивать модель под различные
условия, равно как и за счет выбора весовых коэффициентов.
Таким
образом, применение методов нечеткой логики позволяет решить задачу оценки
уровня специалистов за счет гибкой и легко интерпретируемой модели.
1)
Методы
предварительной обработки нечеткой экспертной информации на этапе ее формализации– 2003 [Электронный ресурс]. – URL: https://cyberleninka.ru/article/n/metody-predvaritelnoy-obrabotki-nechetkoy-ekspertnoy-informatsii-na-etape-ee-formalizatsii/viewer
(дата обращения: 22.10.2019)
2)
Методы
планирования выполнения задач в системах реального времени – 2001 [Электронный ресурс]. – URL: http://www.swsys.ru/index.php?page=article&id=854/
(дата обращения:25.10.2019).
3)
Основы
прогнозирования – 2007 [Электронный ресурс] URL:
https://www.monographies.ru/ru/book/section?id=166
(Дата
обращения: 25.10.2019).
