Введение
В современном мире существует множество информационных систем, успешно выполняющих те или иные задачи, системы мониторинга заказов на строительных рынках не исключение. На просторах российского интернета можно насчитать приблизительно 100 сайтов, предлагающих данные услуги, среди которых приблизительно от 5 до 10 являются авторитетными. Исходя из этого возникает разумный вопрос: «Необходима ли еще одна ИС мониторинга заказов на строительном рынке?». Огромное количество готовых решений, казалось, предоставляющих всё необходимое имеют небольшой ряд серьёзных недостатков, которые будут рассмотрены для каждой из групп ИС.
1. Разновидности информационных ресурсов
В наше время хорошую информационную систему можно заприметить с первого раза взглянув лишь на сайт. Обычно такие решения имеют красивую, лаконичную страничку в интернете, на которой понятно все расписано, такая ИС внушает надежность, что очень важно, однако сразу же бросается и их главный минус – необходимость регистрации и наличие платного контента.
В современных реалиях, даже для того, чтобы опробовать продукт нужна регистрация, которая сулит определенного рода рисками такими, как спам или что хуже продаже ваших данных другим корпорациям.
Хорошим вариантом для бизнеса могли бы стать остальные 90-95 процентов решений, для которых регистрация и оплата услуг не требуется, но их главный минус – невозможность просмотра содержимого сайтов. Именно поэтому задача – разработать ИС мониторинга, которая будет предоставлять текущие данные по рынку в удобном к прочтению и отсортированном виде, является более чем оправданной и актуальной.
К группе бесплатных ресурсов относятся следующие Интернет-ресурсы:
· РосТендер
· Единая электронная торговая площадка
· Тендеры Уфы
· АО УЗЭМИК
· IS-ZAKUPKI
· Bicotender
В то время как к платным относятся так называемые сайты-агрегаторы, которые, как правило, заимствуют всю необходимую информацию с других более простых, грубо сделанных ресурсов, к которые были приведены выше:
· TRANSPOREON
· Тендерплан
· B2Bcenter
· ЭТП ГПБ
· Goszakaz.ru
· контур.закупки
2. Алгоритмы поиска «нужного» текста
Одной из главных задач сайтов-агрегаторов состоит даже не в том, чтобы собирать информацию, а в том, чтобы правильно ее обрабатывать, классифицируя и группируя по разным разделам для более комфортного просмотра и работы с ней.
Для достижения данной цели хорошо подойдут следующие алгоритмы быстрого поиска массивов строк в тексте:
· Алгоритм Ахо – Корасик (Aho – Corasick algorithm)
· Алгоритм Рабина – Карпа
Первый способ характеризуется довольно сложной логикой построения дерева и обработки «возвратов» и у него существует множество примеров реализации.
Алгоритм Ахо – Корасик – это алгоритм, который определяет местонахождение множества шаблонов в тексте строки. Сначала он создает детерминированные конечные автоматы для всех предопределенных шаблонов, а затем, используя автомат, обрабатывает текст за один проход. Он состоит из построения автоматов сопоставления с образцом конечного состояния из шаблонов и последующего использования автоматов сопоставления с образцом для обработки текстовой строки за один проход.
Автомат или дерево ключевых слов для множества шаблонов P – это дерево с корнем K, такое что:
1. Каждое ребро е в К отмечено лишь одним символом.
2. Любые два ребра, которые исходят из одной вершины, имеют разные метки.
Лучше всего представить метку вершины v как объединение меток ребер, которые составляют путь из корня в вершину v, и обозначить ее как L(v).
3. Для каждого шаблона Pi из множества P есть такая вершина v, при которой L(v) = Pi.
4. Метка каждой вершины является шаблоном из множества P.
Пример префиксного дерева для P = {he, she, his, hers}:
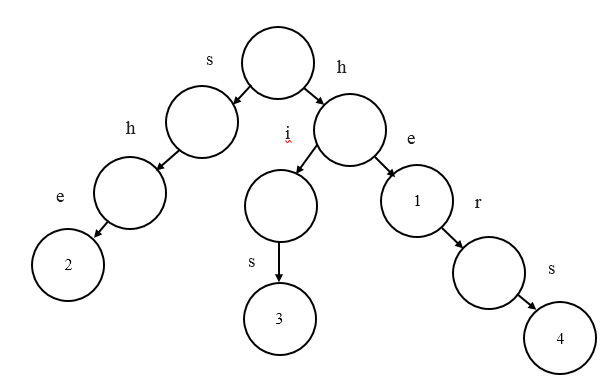
Рисунок 1 – Автомат
Отличительная особенность второго алгоритма – эффективная работа с очень большими наборами слов. Используя хеширование данный алгоритм ищет подстроку.
Причиной производительности алгоритма Рабина – Карпа являются низкая вероятность коллизий и эффективное вычисление хеш-значения последовательных подстрок текста. Рабин и Карп предложили использовать так называемый полиномиальный хеш. Для данного шаблона s такой хеш определён следующим образом:
![]()
где q – некоторое простое число, а x – число от 0 до q-1.
3. Критерии хорошего графического пользовательского интерфейса
Каждая хорошо работающая информационная система должна предоставлять необходимые данные пользователю в доступном — понятном к прочтению, а, главное, пониманию виде. При первом использовании системы она должна быть понятной на интуитивном уровне, чтобы, если обучение необходимо, пользователь без проблем мог разобраться в ней.
Хорошими ориентирами при создании графических оболочек информационных систем являются следующие, тщательно подобранные 3 критерия, определяющие в первую очередь не то, как выглядит интерфейс, а то насколько удобно им пользоваться:
· Закон Фиттса:
Основная его идея заключается в том, что время, необходимое для достижения цели, зависит от размера цели и расстояния до неё.
Закон Фиттса предоставляет модель движения человека, созданную в 1954 году Полом Фиттсом, которая может точно предсказать количество времени, необходимого для перемещения и выбора цели. Хотя первоначально закон Фиттса разрабатывался в соответствии с движением в физическом мире, он обычно применяется к движению через графический интерфейс пользователя с использованием курсора или другого типа указателя. Закон Фиттса был сформулирован математически несколькими способами; однако его предсказания согласуются во многих различных математических представлениях.
Закон Фиттса записывается следующим образом:
![]()
где:
T – среднее время, затрачиваемое на совершение действия
a – среднее время запуска/остановки движения
b – величина, зависящая от типичной скорости движения
D – дистанция от точки старта до центра цели
W – ширина цели, измеренная вдоль оси движения
· Закон Хика – Хаймана:
Смысл данного закона заключается в том, что время, требуемое для выполнения выбора, возрастает с количеством и сложностью самих вариантов выбора.
Закон Хика (или закон Хика – Хаймана) назван в честь британской и американской команды психологов Уильяма Эдмунда Хика и Рэя Хаймана. В 1952 году эта пара приступила к изучению взаимосвязи между количеством имеющихся стимулов и временем реакции человека на любой данный стимул. Как и следовало ожидать, чем больше стимулов для выбора, тем больше времени требуется пользователю, чтобы принять решение о том, с кем взаимодействовать. Пользователям, которым предоставляется множество вариантов, нужно время, чтобы интерпретировать и принять решение в их отношении, что зачастую они не хотят делать.
Для n одинаково вероятных вариантов, среднее время реакции Т, необходимое для выбора из вариантов, составляет приблизительно:
![]()
где b – постоянная, которая может быть определена эмпирически путем подгонки линии к измеренным данным. Логарифм выражает глубину иерархии «дерева выбора» – log2 указывает, что был выполнен двоичный поиск. Добавление от 1 до n учитывает «неопределенность относительно того, отвечать или нет, а также о том, какой ответ делать».
В случае выбора с неравными вероятностями закон можно обобщить следующим образом:
![]()
где H тесно связана с теоретико-информационной энтропией решения, определяемой как
![]()
где pi относится к вероятности i-й альтернативы, дающей теоретико-информационную энтропию. Закон Хика по форме похож на закон Фиттса. Закон Хика имеет логарифмическую форму, потому что люди подразделяют общую коллекцию вариантов на категории, исключая примерно половину оставшихся вариантов на каждом шаге, вместо того, чтобы рассматривать каждый выбор один за другим, что потребует линейного времени.
· Золотое сечение
Золотое сечение – это соотношение частей друг к другу 1: 1.618.
Данный принцип описывает математическую пропорцию, которая формирует гармоничное, естественное отношение частей одного целого друг к другу. Ее получают, разделяя целое на две части так, чтобы отношение первой части ко второй было таким же, как отношение всего целого к первой части. Важным при построении интерфейсов является правило третей, которое применяют для зонирования элемента и управления вниманием пользователя. Суть заключается в делении элемента на три равных части по горизонтали или вертикали. Пересечения линий — точки максимального притяжения внимания. Быстро сканируя интерфейс взглядом, люди чаще всего фокусируются на элементах, которые находятся на этих точках или рядом с ними.
Заключение
В данной работе были рассмотрены существующие информационные ресурсы, предоставляющие информацию по строительным тендерам, предложена их классификация, а также отмечены их главные основополагающие недостатки, преимущества и функциональные возможности.
Были описаны и рассмотрены наиболее эффективные математические методы поиска массивов строк для определения соответствия строк запрошенным темам, фильтрации, классификации: алгоритм Ахо – Корасик и алгоритм Рабина – Карпа, каждый из которых имеет свои преимущества и недостатки.
В заключительной части были выделены минимальные критерии, которые необходимо учитывать при создании графической оболочки любой информационной системы, ими оказались: закон Хика, закон Фиттса и правило золотого сечения.
СПИСОК ЛИТЕРАТУРЫ
1. Когаловский М. Р. Перспективные технологии информационных систем. М.: ДМК Пресс. C.12-13.
2. Куликов Г.Г., Сулейманова А.М., Старцев Г.В., Шилина М.А.
Вестник ВЭГУ. 2011. №5(55). С. 24.
3. Алгоритм Рабина – Карпа – Википедия [Электронный ресурс]: Википедия – свободная энциклопедия. URL: https://ru.wikipedia.org/wiki/Алгоритм_Рабина_—_Карпа
4. Алгоритм Ахо – Корасик – Википедия [Электронный ресурс]: Википедия – свободная энциклопедия. URL: https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm
5. 10 правил, которые нужно учитывать при разработке интерфейсов [Электронный ресурс]: Tproger. URL: https://tproger.ru/translations/psychology-laws-in-ux-and-ui-development/
6. Золотое сечение в дизайне интерфейсов [Электронный ресурс]: UXPUB. URL: https://ux.pub/zolotoe-sechenie-v-dizajne-interfejsov/
7. V. Aho, M. J. Corasick, “Efficient string matching: An aid to bibliographic search”, Communications of the ACM, 18:6 (1975), 333–340.
8. Антонов Е.С. RSDN Magazine. 2011.№1. С. 60-67.
