Наиболее распространенной причиной миграции является необходимость перемещения данных в новую систему для увеличения масштаба и обеспечения роста объема. Другие причины включают в себя: замена устаревших систем, уменьшение объема хранилища за счет перехода на систему, конкурентоспособность путем внедрение передовых технологий, перенос данных в облако, что исключает затраты на локальную ИТ-инфраструктуру.
Исходя из вышесказанного миграция данных может быть разделена на четыре типа:
Миграция базы данных
Этот тип миграции включает перемещение данных между двумя ядрами базы данных.
Миграция приложений
Этот тип миграции происходит, когда организация переключается с одной платформы или приложения поставщика на другое.
Облачная миграция
В облачной миграции полные или частичные информационные активы, приложения или службы организации развертываются в облаке.
Методы переноса данных
Рассмотрим некоторые из них:
ETL
Процессы извлечения, преобразования и загрузки данных позволяют выполнять множество операций в проектах в области информационных технологий.
Извлечение, преобразование, загрузка данных (ETL) – это процесс копирования данных из одного или нескольких источников в целевую систему, которая обычно предназначена для представления данных в отличие от источника(ов). Процессы ETL используются для хранилищ данных, интеграции данных и проектов миграции данных.
Извлечение данных включает извлечение данных из однородных или разнородных источников
Методы преобразования данных часто очищают, агрегируют, дедуплицируют и другими способами преобразуют данные в правильно определенные форматы хранения для запроса и анализа.
Загрузка данных представляет собой вставку данных в конечное целевое хранилище, такое как хранилище оперативных данных, витрина данных или хранилище данных.
Процессы ETL обычно объединяют данные из нескольких приложений (систем и источников), возможно, разработанные и поддерживаемые различными поставщиками или размещенные на отдельном компьютерном оборудовании. Отдельные системы, содержащие исходные данные, часто управляются и управляются разными командами. Перед проектированием и разработкой ETL-процессов всегда требуется сопоставление данных от источника к цели. Логические карты данных (обычно готовые в виде электронных таблиц) описывают отношения между начальными точками и конечными точками системы ETL.
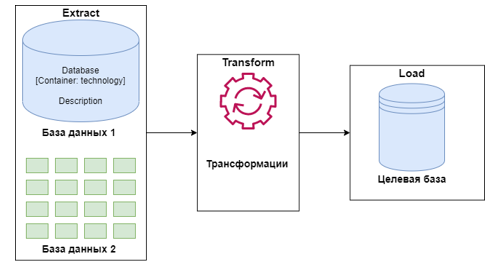
Рис. 1 ETL процесс
Шаги для процессов ETL:
Процессы ETL состоят из трех отдельных, но важных функций, которые часто объединяются в единый инструмент программирования, который помогает в подготовке данных и в управлении базами данных.
После обнаружения и записи исходных данных тщательно разработанные процессы ETL извлекают данные из исходных систем, внедряют задачи качества данных / стандарты согласованности, согласовывают данные, чтобы отдельные источники могли использоваться вместе, и, наконец, доставляют данные в готовом для представления формате, чтобы разработчики приложений могут создавать приложения, а конечные пользователи могут принимать решения.
Обнаружение исходных данных
Некоторые или все исходные системы могли быть идентифицированы во время сеансов моделирования данных проекта, но это не может считаться само собой разумеющимся. Обычно на этапе моделирования данных проекта определяются только ключевые исходные системы. Команда ETL должна углубиться в требования к данным, чтобы определить каждую исходную систему, таблицу и атрибут, требуемые в процессах ETL. Определение необходимых источников данных или систем записи для каждого элемента / таблицы – это задача, которую необходимо решить, прежде чем переходить к извлечениям данных.
Извлечение исходных данных
Фазы извлечения данных представляют собой извлечения из исходных систем, чтобы сделать их доступными для дальнейшей обработки.
Типы извлечения данных:
- Полное извлечение – полное извлечение всех данных необходимо каждый раз, когда требуются измененные данные из этих отдельных источников. Полная выписка требует сохранения копии последней выписки в том же формате, чтобы определить изменения, когда станет доступной более поздняя выписка. Команда ETL отвечает за регистрацию изменений содержимого данных во время дополнительных нагрузок после начальной загрузки.
- Обновление извлечения – когда исходные системы могут предоставлять уведомления об изменении определенных данных и дополнительно идентифицировать каждое изменение, это самый простой способ извлечения данных.
- Инкрементное извлечение. Некоторые исходные системы не могут предоставить уведомление о том, что произошло обновление, но они могут определить, какие записи были изменены, и предоставить выдержку только из этих записей. Во время последующих шагов ETL система должна идентифицировать изменения и распространять их вниз.
Преобразование данных
Данные, извлеченные из источников, часто являются результатом транзакций и поэтому не могут использоваться в целевых базах данных в такой форме. Большая часть таких исходных данных должна быть очищена, дедуплицирована, агрегирована или иным образом преобразована. Это ключевой шаг, когда процесс ETL добавляет ценность и изменяет данные так, чтобы можно было генерировать проницательные отчеты о приложениях.
Репликация базы данных
Проще говоря, репликация данных берет данные из исходных баз данных – Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB и т. д. – и копирует их в облачное хранилище данных. Это может быть одноразовая операция или постоянный процесс, когда ваши данные обновляются. Поскольку ваше хранилище данных является важным механизмом, с помощью которого вы можете получить доступ и анализировать ваши данные, необходима правильная репликация данных, чтобы не потерять, не продублировать или иным образом не испортить ценную информацию.
Давайте обратимся к каждому из трех распространенных методов репликации данных.
- Полный дамп и загрузка. Начиная с самого простого метода, полная репликация дампов и загрузок начинается с определения интервала репликации (может быть два, четыре, шесть часов – в зависимости от ваших потребностей). Затем в каждом интервале запрашиваемые вами таблицы запрашиваются и делается снимок. Новый снимок (дамп) заменяет (загружает) предыдущий снимок в вашем хранилище данных.
- Инкремент: с помощью метода инкремента вы определяете индикатор обновления для каждой из ваших таблиц – обычно это столбец, который отслеживает время последнего обновления (обычно что-то вроде «updated_at»). Каждый раз, когда строка в вашей базе данных вставляется или обновляется, индикатор обновления обновляется. Ваши таблицы данных регулярно запрашиваются для сбора изменений. Изменения копируются в ваше хранилище данных и объединяются.
- Репликация журналов или сбор данных изменений (CDC). Самый быстрый метод – более или менее золотой стандарт репликации данных – это репликация журналов или CDC. Это включает в себя запрос внутреннего журнала изменений вашей базы данных каждые несколько секунд, копирование изменений в хранилище данных и частое их включение. Все изменения в указанных вами таблицах и объектах загружаются по умолчанию, включая удаление, поэтому ничего не пропадает.
Список использованных источников
- Tehreem Naeem Data Migration – The Why, The What, and The How [Электронный ресурс]. – Режим доступа: https://www.astera.com/type/blog/data-migration-software/ (дата обращения: 15.01.20)
- Wayne Yaddow FOUNDATIONS OF DATA EXTRACTION TRANSFORM LOAD (ETL) [Электронный ресурс]. – Режим доступа: https://www.ewsolutions.com/foundations-of-data-extraction-transform-load-etl (дата обращения: 15.01.20)
- Garrett Alley Database Replication: Getting Your Data from There to Here [Электронный ресурс]. – Режим доступа: https://www.alooma.com/blog/database-replication-methods (дата обращения: 15.01.20)
