Процессорное время является одним из самых ограниченных ресурсов вычислительной системы. Для того чтобы его распределить между многочисленными процессами в системе необходимо использовать процедуру планирования процессов. Различают следующие виды планирования процессов (по длительности влияния): краткосрочное, среднесрочное и долгосрочное [4]. В данной статье мы рассмотрим методы краткосрочного планирования.
Для краткосрочного планирования в качестве динамических характеристик процессов могут применяться следующие сведения:
- Какое количество времени потребовалось для выгрузки процесса на накопитель или его загрузки в оперативную память.
- Какое количество оперативной памяти захватывает процедура.
- Какое количество процессорного времени ранее дано процессу.
- CPU burst.
- I/O burst.
Поясним значение двух последних параметров, длительность которых, считается значимым динамическим параметром процесса. Работу каждого процесса можно представить, как очередность циклов применения процессора и ожидания окончания действий ввода-вывода. Период времени постоянного применения процессора носит наименование CPU burst, а период времени постоянного ожидания ввода-вывода – I/O burst [8]. На рисунке 1 представлен отрывок работы определенного процесса с выделением указанных интервалов.

Рисунок 1. Фрагмент деятельности процесса с выделением промежутков
Одним из наиболее простых алгоритмов планирования является First-Come – First-Served (первым пришел, первым обслужен). Его обычно обозначают – FCFS по первым буквам его английского названия. Предположим, что процессы, пребывающие в состоянии готовности, выстроены по очереди. Если процесс переходит в положение готовность, он, а конкретнее, ссылка в его РСВ переходит в конец данной очереди. Подбор следующего процесса с целью выполнения осуществляется из начала очереди с того места ссылки в его РСВ. Очередность такого вида содержит в программировании специализированное название – FIFO – сокращение от First In, First Out (первым прибыл, первым вышел) [11].
Данный алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в распоряжение процессор, занимает его до истечения настоящего CPU burst. Затем для выполнения выбирается следующий процесс из начала очереди.
Преимуществом алгоритма FCFS является простота его реализации, но в то же время он обладает множеством минусов [9]. Рассмотрим следующий пример. Пусть в состоянии готовность находятся три процесса – для которых известны времена их очередных CPU burst. Эти времена приведены в таблице на рисунке 2 в некоторых условных единицах.

Рисунок 2. Времена очередных CPU burst
Для легкости понимания будем считать, что работа процессов ограничивается применением только лишь одного промежутка CPU burst, что процессы не делают действий ввода-вывода и что время переключения контекста так незначительно, что его можно не брать во внимание.
Если процессы, готовые к выполнению, расположены в порядке , то картина их исполнения выглядит следующим образом (рис. 2). Первым выполняется процесс ?0. П олучает его на все своего CPU burst, то есть на единиц времени. Затем, когда процесс p0 будет выполнен, начнет свое выполнение новый процесс – . Время, на которое он займет процессор, составит уже четыре единицы. Далее, за процессом , следует процесс p2. Следовательно, время ожидания для процесса равно нулю, для процесса единиц (время выполнения процесса ), а для , соответственно – 17 единиц (сумму времени, ушедшего на выполнение процессов p0 и p1). Расчитаем среднее время выполнения процесса. Оно составит
Тогда, рассчитаем среднее полное время: единицам времени.
Если изменить порядок расположения процессов, и расположить их следующим образом: , то их выполнение будет происходить следующим образом (рис. 3).
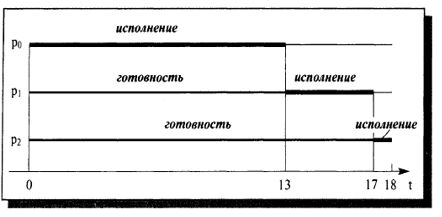
Рисунок 3. Выполнение процессов в порядке
Ожидание выполнения процесса составит Тогда, ожидание д 0 единиц.
Тогда рассчитаем среднее время ожидания: Что в пять раз меньше, чем в случае, рассмотренном ранее, когда процессы распологались следующим образом: Проверим, уменьшилось ли полное время выполнения процессов. Полное время выполнения для процесса ?0 равно 18 , ?1− 5 единицам, ?2−1 единице. Тогда, среднее полное время: . Это, как мы и предполагали, меньше, чем при расстановке процессов первым способом (в два раза) [4].

Рисунок 4. Выполнение процессов в порядке
Как можно заметить, среднее время ожидания, как и среднее полное время выполнения для данного алгоритма в значительной степени зависят от расположения процессов в очереди. Если мы имеем процесс с длительным CPU burst, то короткие процессы, которые перешли в состояние готовность после длительного процесса, будут достаточно длительное время ждать начала выполнения. В связи с этим алгоритм FCFS почти не используется для систем разделения времени – слишком большим получается среднее время отклика в интерактивных процессах.
Модификацией алгоритма FCFS является алгоритм под названием Round Robin (Round Robin – это вид детской карусели в США), сокращенно записывается как – RR [8]. Вообще говоря, данный алгоритм представляет собой алгоритм FCFS, но в не вытесняющем режиме планирования. Легко описать данный вид планирования можно взглянув на его название. Все процессы находятся в определенном цикле «сидят на карусели» [9]. Эта «карусель» вращаясь, позволяет каждому из процессов находиться около процессора определенный промежуток времени, который, как правило, составляет от десяти до ста миллисекунд. Нахождение около процессора, позволяет процессу выполняться.
Исполнение данного алгоритма осуществляется аналогично предыдущему, при помощи формирования процессов, находящихся в состоянии готовности в очередь FIFO.
Для каждого следующего исполнения планировщик выбирает первый в очереди процесс и отмеряет промежуток времени для генерации прерывания по истечении определенного промежутка времени. Возможны два варианта выполнения процесса [4]:

Рисунок 5. Процессы на карусели
Для наглядности посмотрим как будет работать данный алгоритм на предыдущем примере со следующим порядком процессов и квантом времени равным 4. Как происходит выполнение данных процессов изображено в таблице 1.
Таблица 1. Выполнение процессов
|
Время
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
|
р0
|
И
|
И
|
И
|
И
|
Г
|
Г
|
Г
|
Г
|
Г
|
И
|
И
|
И
|
И
|
И
|
И
|
И
|
И
|
И
|
|
р1
|
Г
|
Г
|
Г
|
Г
|
И
|
И
|
И
|
И
|
|
|
|
|
|
|
|
|
|
|
|
р2
|
Г
|
Г
|
Г
|
Г
|
Г
|
Г
|
Г
|
Г
|
И
|
|
|
|
|
|
|
|
|
|
Буквой «И» обозначены процессы, которые находятся в режиме исполнение, а буквой «Г» соответственно процессы, которые находятся в режиме готовности. Ячейки завершенных процессов пусты.
Столбцы таблицы – это единицы времени на протяжении которых процессы находятся в определенном режиме, так столбец с цифрой «1» соответствует промежутку времени от 0 до 1 и т.д.
Итак, первым в очереди к исполнению будет процесс Длительность исполнения данного процесса не вмещается в единицу времени, но процесс времени исполняется до истечения кванта следовательно CPU burst занимает 4 единицы времени. Затем, он становится последним в очереди процессов, которые готовы к исполнению. Следовательно, очередь будет выглядеть следующим образом Теперь начинается выполнение процесса В данном случае величина выделенного кванта равна времени исполнения процесса, поэтому процесс будет продолжать работу до завершения. Очередь процессов, которые находятся в состоянии готовности теперь будет содержать только два процесса Начинает свое выполнение процесс который завершается за то процессорное время, которое было ему отпущено. Теперь, единственным процессом, который еще не закончил свою работу является процесс поэтому все оставшиеся кванты времени отводятся ему.
Посчитаем число символов «Г» (время ожидания для процесса) для каждой строки соответственно процессам: для – 5 единиц времени, для 4 единиц времени, для 8 единиц времени. Расчитаем среднее время ожидания для данного алгоритма: единиц времени. Аналогично посчитаем полное время выполнения для каждого процесса: 8 единиц, для процесса 9 единиц. Среднее полное время выполнения оказывается равным +8+9)/3 единицам времени.
Несложно заметить, что, как и для алгоритма FCFS, среднее время ожидания равно 2, а среднее полное время выполнения равняется 6 единицам времени.
С совершенствованием алгоритма многоуровневых очередей к нему добавился механизм обратной связи. Заключается он в том, что процесс не приписан к определенной очереди на постоянной основе, а способен перемещаться между очередями в зависимости от своего поведения.
Для наглядности разберем случай, когда процессы, находящиеся в состоянии готовности сформированы в 4 очереди. Планирование процессов между очередями строится на базе вытесняющего приоритетного механизма.
Чем выше на рисунке расположена очередь, тем выше ее приоритет. Процессы в первой очереди не будут выполняться, если в очереди ноль есть хотя бы один процесс. Процессы в очереди 2 не смогут, если есть хотя бы один процесс в очередях 0 и 1. И в конечном итоге, процесс в очереди 3 может исполниться только тогда, когда очереди 0,1 и 2 пусты.
Если при работе одного процесса появляется другой, который находится в наиболее приоритетной очереди, то исполняющийся в данный момент процесс вытесняется новым. Планирование процессов для очередей 0-2 основывается на алгоритме RR, а планирование процессов в очереди 3 на алгоритме FCFS.
Появившийся процесс переходит в очередь 0. В его распоряжении входит квант времени равный 8 единицам измерения. Далее, процесс либо остается в данной очереди, если квант времени больше продолжительности его CPU burst, либо переходит в очередь. В первой очереди квант времени процессов равен 16 единицам. Если же процесс не укладывается и в это время, то он мигрирует в следующую очередь, в противном случае остается в очереди 1. В очереди 2 размерность кванта времени равна 32 единицы. По аналогии, процесс либо остается в очереди 2, либо переходит в очередь 3, которая не имеет величины квантового времени, то есть готовых процессов в других очередях нет, процесс может продолжать выполнение до завершения своего CPU burst.
Для процесса приоритетность очереди, в которую он попадет, зависит от продолжительности его CPU burst. Процессы с наименьшим значением продолжительности CPU burst попадают в наиболее приоритетные очереди, но, вместе с тем, они не могут рассчитывать на большое процессорное время. В результате, все процессы распределяться по высоко- и низкоприоритетным очередям соответственно требованиям времени работы процессора.
Размещение процессов в противоположном порядке может реализовываться по разным принципам. Миграция процессов занимающих низкоприоритетную очередь в очередь высокоприоритетную позволяет подробнее учесть изменение поведения процессов во времени [1].
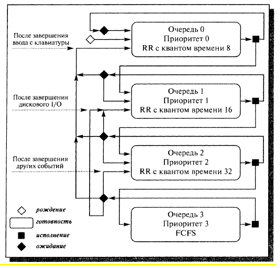
Рисунок 6. Схема миграции процессов Multilevel Feedback Queue
Данный алгоритм, по сравнению с другими выше рассмотренными, является наиболее общим аспектом планированию процессов. Многоуровневые очереди с обратной значительно сложнее в реализации, но в свою очередь владеют большей степенью гибкости [11]. Понятно, что кроме варианта, приведенного выше, существует множество других модификаций данного способа планирования.
Для разработки приложения была выбрана программа Delphi Second edition v 7.2. Алгоритмы, рассмотренные в первой части, были протестированы, а результаты работы разработанного приложения представлены в виде скриншотов во второй части.
В разработке приложения использовались следующие модули: Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls, Grids.
Рассмотрим примеры работы программы, используя различные алгоритмы планирования. Главная форма приложения содержит строку выбора алгоритма:
- First-Come – First-Served
- Round Robin
- Multilevel Feedback Queue (рис. 7).
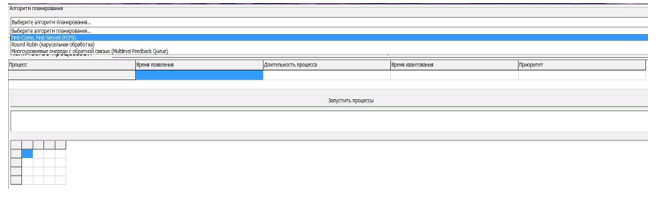
Рисунок 7. Главная форма приложения
На выполнение процессов, в зависимости от алгоритма, будут влиять разные параметры. Так, результат работы алгоритма FCFS зависит только от времени запуска процесса и от его длительности. Как мы видим, все процессы выполняются друг за другом по времени запуска, не прерываясь, до своего исполнения (рис. 8).

Рисунок 8. Результат работы алгоритма FCFS.
Результат же работы алгоритма Round Robin зависит еще и от времени квантования (промежуток времени, в который процесс находится около процессора). Так, рассмотрим как исполняется процесс 2 на рисунке 9 ниже.

Рисунок 9. Результат работы алгоритма RR.
Он запускается первым, его длительность равна 3, но в режиме исполнения он находится только две единицы времени, так как время его квантования равно 2. Затем, начинает исполняться следующий процесс в течение времени его квантования или до полного завершения.
На исполнение алгоритма Multilevel Feedback Queue оказывает значительное влияние такой параметр как приоритет.

Рисунок 10. Результат выполнения алгоритма MFQ.
В ходе проведения работы были изучены и проанализированы алгоритмы планирования и средства, позволяющие создавать учебные приложения. Наиболее подходящими для выполнения поставленной задачи оказался структурированный объектно-ориентированный язык программирования Delphi 7 Second edition v 7.2.
Разработанное учебное приложение наглядно демонстрирует работу алгоритмов планирования процессорного времени. Благодаря его использованию, можно отследить какой из алгоритмов в зависимости от заданных параметров занимает меньше процессорного времени, а значит, является более эффективным.
Литература
[1] Бакнелл Д. Фундаментальные алгоритмы и структуры данных в Delphi. – Питер, 2006.
[2] Белов В.В. Программирование в Delphi: процедурное, объектно-ориентированное, визуальное: Учебное пособие для вузов / В.В. Белов, В.И. Чистякова. – М.: ГЛТ, 2014.
[3] Бобровский С. Delphi 7. Учебный курс. – Питер, 2006.
[4] Олифер В.Г., Олифер Н.А. Сетевые операционные системы. – СПб.: Издательский дом Питер, 2001.
[5] Санников Е. Курс практического программирования в Delphi. Объектно-ориентированное программирование / Е. Санников. – М.: Солон-пресс, 2013.
[6] Сорокин А. Delphi. Разработка приложений.– СПб. : Питер, 2011.
[7] Сухарев М. Золотая книга Delphi. – Наука и техника, 2008.
[8] Таненбаум Э. Современные операционные системы. – СПб.: Издательский дом Питер, 2015.
[9] Фаронов В. Delphi. Программирование на языке высокого уровня / В. Фаронов. – СПб.: Питер, 2012.
[10] Фуфаев Э. Delphi проекты. – М. : Aсademia, 2013.
[11] Чеснокова О. Delphi 2007. Алгоритмы и программы. – НТ Пресс, 2008.
References
[1] Bucknell D. Fundamental algorithms and data structures in Delphi. – Peter, 2006.
[2] Belov V. V. Programming in Delphi: procedural, object-oriented, visual: textbook for universities / V. V. Belov, V. I. Chistyakova. – Moscow: GLT, 2014.
[3] Bobrovsky S. Delphi 7. Training course. – Peter, 2006.
[4] olifer V. G., olifer N. A. Network operating systems. – SPb.: Peter publishing house, 2001.
[5] Sannikov E. Course of practical programming in Delphi. Object-oriented programming / E. Sannikov. Moscow: Solon press, 2013.
[6] Sorokin A. Delphi. Application development.– SPb. : Peter, 2011.
[7] Sukharev M. Golden book Delphi. – Science and technology, 2008.
[8] Tanenbaum E. Modern operating systems. – SPb.: Peter publishing house, 2015.
[9] V. Faronov Of Delphi. Programming in a high-level language / V. Faronov. – SPb.: Peter, 2012.
[10] Fufaev E. Delphi projects. – Moscow: Academia, 2013.
[11] Chesnokova O. Delphi 2007. Algorithms and programs. NT Press, 2008.
