Теорема Байеса названа в честь автора Томаса Байеса. Впервые теорема была опубликована после смерти автора в 1763 году. Позднее данный метод был доработан Лапласом и опубликован в сборнике «Аналитическая теория вероятности». Распространение данный метод получил только с развитием вычислительных мощностей.
Теорема Байеса использует термин вероятности, вероятность представляет из себя степень возможности наступления события. Часто вероятность находится как частота наступления заданных событий ко всем рассматриваемым событиям. Теорема Байеса отражена в формуле (1), где в качестве объекта рассматривается сообщение.
![]() (1)
(1)
где,
![]() – вероятность принадлежности сообщение
– вероятность принадлежности сообщение ![]() к классу
к классу ![]() ;
;
![]() – вероятность встречи сообщение
– вероятность встречи сообщение ![]() среди класса
среди класса ![]() ;
;
![]() – безусловная вероятность встречи сообщение класса
– безусловная вероятность встречи сообщение класса ![]() ;
;
![]() – безусловная вероятность сообщение
– безусловная вероятность сообщение ![]() .
.
Применение теоремы Байеса к задаче к классификации спам сообщений возможна при помощи дополнения [1]. Чтобы определить к какому классу принадлежит сообщение необходимо посчитать вероятность принадлежности для каждого класса и выбрать класс, с максимальной вероятностью. Если записать данное утверждение в виде уравнения, то оно будет иметь следующий вид (2)
![]() (2)
(2)
Так как безусловная вероятность сообщения ![]() , находящееся в знаменателе представляет из себя константу и не влияет на ранжирование классов, то можно преобразовать уравнение (2) исключив из него безусловную вероятность сообщения
, находящееся в знаменателе представляет из себя константу и не влияет на ранжирование классов, то можно преобразовать уравнение (2) исключив из него безусловную вероятность сообщения ![]() , и получить уравнение виде (3):
, и получить уравнение виде (3):
![]() (3)
(3)
Уравнение (3) рассчитывает вероятность для сообщения целиком, чтобы повысить точность необходимо сообщение представить в виде набора слов, для это необходимо добавить аппроксимацию произведения условных вероятностей для слов в сообщении, для этого преобразуем часть формулы (3) в формулу (4):
![]() (4)
(4)
Из-за независимости появления слов в классе от контекста Байесовский алгоритм называю наивным. Применив формулу (4) к формуле (5) получим формулу (6)
![]() (6)
(6)
Поскольку при большой длине сообщения, будет перемножение большого количества мелких величин, то может возникнуть арифметической переполнение снизу, во избежание данной проблемы используем следующее свойство логарифма, представленное в формуле (7)
![]() (7)
(7)
Учитывая свойство произведения логарифма (7) и монотонность будет корректным добавить аппроксимацию логарифма к уравнению (6) получив формулу (8) не учитывая основание логарифма, так как оно в данном случае не будет влиять на выразительность данных. Полученные значения из уравнения (8) будут более удобным для дальнейшего анализа.
![]() (8)
(8)
Оценка вероятности ![]() и
и ![]() происходит на обучающей выборке, а вероятность класса рассчитывается по формуле
происходит на обучающей выборке, а вероятность класса рассчитывается по формуле
![]() (9)
(9)
где
![]() – количество сообщений, принадлежащих классу
– количество сообщений, принадлежащих классу ![]() ;
;
![]() – общее количество сообщений в обучающей выборке.
– общее количество сообщений в обучающей выборке.
Для нахождения вероятности слова в классе используется отношение частоты встречаемости рассчитываемого слова деленое на количество уникальных слов, данное утверждение представлено в виде формулы (10).
![]() (10)
(10)
где
![]() – количество раз встречаемости рассчитываемого слова в сообщениях класса
– количество раз встречаемости рассчитываемого слова в сообщениях класса ![]() ;
;
V – список уникальных слов.
Формула (10) не учитывает проблему неизвестных слов, появившихся после этапа обучения. То есть если во время классификации тестовой выборки появится слово, которого не было на этапе обучения, то значение ![]() будет нулевым. Если
будет нулевым. Если ![]() будет равно нулю, то сообщение нельзя будет отнести ни к какой категории. Решить данную проблему путем учета всех слов в обучающей выборки с учетом опечаток невозможно. Для решения проблемы неизвестных слов будет использоваться сглаживание Лапласа. Идея заключается в том, что алгоритм воспринимает каждое слово так, как будто видел каждое слово на один раз больше, то есть прибавляет единицу к частоте каждого слова.
будет равно нулю, то сообщение нельзя будет отнести ни к какой категории. Решить данную проблему путем учета всех слов в обучающей выборки с учетом опечаток невозможно. Для решения проблемы неизвестных слов будет использоваться сглаживание Лапласа. Идея заключается в том, что алгоритм воспринимает каждое слово так, как будто видел каждое слово на один раз больше, то есть прибавляет единицу к частоте каждого слова.
![]() (11)
(11)
Применение сглаживания Лапласа делает смещение вероятностной оценки в сторону менее вероятных исходов и неизвестные слова на этапе обучения модели получают не нулевую вероятность.
Рассмотрим такое решение проблемы на практическом примере, допустим есть модель, которая обучается именами, и на этапе обучения были имена представленные в таблице 1, где в левой колонке указаны имена, а в правой частота их встречи в тексте.
Таблица 1– Список имен для примера
|
Имя |
Частота |
|
Миша |
3 |
|
Паша |
2 |
|
Данил |
1 |
После обучения на этапе классификации в тестовой выборке встретится имя Валера, которого не было на этапе обучения. Тогда оценки вероятностей смещенной и оригинальной будут выглядеть следующим образом, вероятность распознавания имени Миша снизится на 1 десятую, для Паши снизится 4 сотых, а для Данила и Валеры вероятность распознавания возрастет, это видно на рисунке 1.
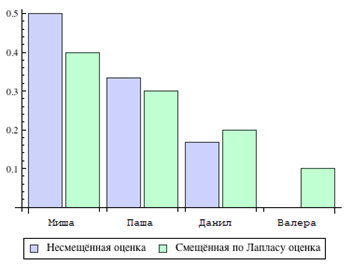
Рисунок 1 – Расчет смещенной и несмещенной оценки
Из гистограммы 1 видно, что результат распознавания ранее неизвестного имени Валера теперь не нулевой, что показывает актуальность применимости метода Лапласа к распознаванию неизвестных слов. Подставив выбранные оценки в уравнение (7) получим формулу байесовского классификатора, учитывавшего проблему неизвестных слов (12).
![]() (12)
(12)
Для того, чтобы реализовать классификатор на основе теоремы Байеса необходимо составить корректную обучающую выборку и собрать следующие данные: количество уникальность слов, частоту встречаемости экземпляров всех классов, относительную частота каждого класса и объем обучающей выборки. После сбора данных, необходимо рассчитать вероятность принадлежности для всех классу по формуле (13), чтобы определить максимальную из них. И к какому классу вероятность принадлежности будет максимальной, к тому классу и принадлежит документ.
![]() (13)
(13)
где
![]() – количество сообщений в обучающей выборке, принадлежащих классу
– количество сообщений в обучающей выборке, принадлежащих классу ![]() ;
;
![]() – общее количество сообщений в обучающей выборке;
– общее количество сообщений в обучающей выборке;
![]() – множество слов классифицируемого сообщения вместе с повторами;
– множество слов классифицируемого сообщения вместе с повторами;
![]() – сколько раз слово с индексом
– сколько раз слово с индексом ![]() встречалось в сообщениях класса
встречалось в сообщениях класса ![]() в обучающей выборке;
в обучающей выборке;
![]() – количество уникальных слов во всех сообщениях обучающей выборки;
– количество уникальных слов во всех сообщениях обучающей выборки;
![]() – суммарное количество слов в сообщениях класса
– суммарное количество слов в сообщениях класса ![]() в обучающей выборке.
в обучающей выборке.
Рассмотрим полученный классификатор, основанный на теореме Байеса на практике, для это возьмем тестовую выборку с сообщениями представлеными в таблице 2:
Таблица 2 – Пример переведенного фрагмента из тестовых данных
|
Спам |
последний день распродажи |
|
Спам |
спешите купить курс маркетинга |
|
Не спам |
надо купить сыр |
Модель классификатора будет использовать обучающую выборку в структурированном виде представленном в таблице 4 и параметры представленный в таблице
Таблица 3 – Параметры для примера работы алгоритма
|
|
Спам |
Не спам |
|
частоты классов |
2 |
1 |
|
количество слов в категории |
6 |
3 |
Такие параметры как частота классов и суммарное количество слов, представленные в таблице 3 необходимы для расчета примера байесовского классификатора.
Таблица 4 – Список слов для демонстрации работы алгоритма
|
|
Спам |
Не спам |
|
Распродажа |
1 |
0 |
|
День |
1 |
0 |
|
Последний |
1 |
0 |
|
Спешите |
1 |
0 |
|
Купить |
1 |
1 |
|
Курс |
1 |
0 |
|
Маркетинг |
1 |
0 |
|
Надо |
0 |
1 |
|
Сыр |
0 |
1 |
Классифицируем фразу «надо купить лекарство». Рассчитаем значение выражения для класса спам (15) по формуле (14):
![]() (15)
(15)
Теперь рассчитаем ту же фразу для класса не спам (16) по формуле (14):
![]() (16)
(16)
Данная фраза будет отнесена к классу не спам, так как выбирается наибольшая вероятность, а в результат вычислений в формуле (16) больше, чем в формуле (15).
Формула (14) имеет недостаток, так как если показатели двух классов будут достаточно близкими, то невозможно будет добавить приоритет какой-либо группе с указанием процента. Реализовать такой приоритет возможно, если данные будут в диапазоне от 0 до 1 и сумма всех вероятностных оценок будет равна 1. Выполнить перечисленные условия можно для формулы (14) сформировав вероятностное пространство, то есть избавившись от логарифма и нормировав сумму по единице.
![]() (17)
(17)
где
![]() – логарифмическая оценка алгоритма для класса
– логарифмическая оценка алгоритма для класса ![]() .
.
В формуле (17) возведение ![]() в степень оценки используется для того, чтобы избавиться от логарифма (
в степень оценки используется для того, чтобы избавиться от логарифма (![]() ).
).
Для фразы «надо купить лекарство» вероятность принадлежности к классу спам по формуле (17) составит 0.327 исходя из расчетов в формуле (18)
![]() (18)
(18)
то есть сообщение является спамом с вероятностью 46.87%, а у на ограничение, что если сообщение не принадлежит к категории спам с вероятностью большей чем 75%, то значит такое сообщение относится к категории не спам.
В библиотеке sklearn алгоритм есть алгоритм байесовского классификатора, и имеет параметр, описанный в формуле (11), который позволяет избежать обнуления неизвестных слов. Зависимость данного параметра от распознавания спама представлена на графике 2.
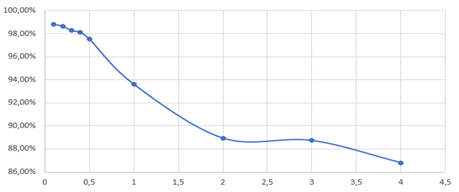
Рисунок 2 – Зависимость параметра для распознавания неизвестных слов от распознавания спама
Из данного графика(рисунок 2) видно, что наилучшее распознавание спама происходит при параметре 0.1, и чем больше его значение, тем меньше процент распознавания.
Проверка на тестовой выборке
Исходные данные состоят из более чем 5000[3] записей на английском языке. В которой есть две группы текстов: спам и общение. Задача классифицирующего алгоритма будет показать как можно более высокий процент на тестовой выборке.
Алгоритм пишется на языке программирования python 3 версии. Построенный алгоритм имеет следующие этапы:
1) считывания слов из файла;
2) преобразования слов с помощью алгоритма Стемминга [2,6];
3) обучение модели на обучающей выборке;
4) проверка алгоритмов на тестовой выборке дает следующие данные смотреть
По результатам тестирования, метод Байеса распознал спам в 98,6% случаев. При тестировании параметр, сглаживающий нулевую вероятность для неизвестных слов, описанный в формуле (11) был равен 0.1.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
1 Ветров, Д.П. Кропотов Байесовские методы машинного обучения: учебное пособие / Д.П. Ветров, Д.А. Кропотов; Формирование системы инновационного образования в МГУ им. М. В. Ломоносова – Москва 2007, – 127 c.
2 Модифицированный алгоритм стеммера Портрета для русского языка: официальный сайт URL:http://snowball.tartarus.org/algorithms/russian/stemmer.html (дата обращения 21.04.2019)
3 Данные для тестирования алгоритма : официальный сайт
URL: https://www.kaggle.com/team-ai/spam-text-message-classification (дата обащения 20.05.2020)
4 Агеев, М. С. «Отправная точка» для дорожки по поиску в РОМИП (предварительный анализ) / М. С. Агеев, Б. В. Добров, Лукашевич Н. В.; Труды РОМИП’2003 (Российский семинар по Оценке Методов Информационного Поиска) – НИИ Химии СПбГУ / Под ред. И. С. Некрестьянова – Санкт-Петербург, 2003 –110 c.
5 Загорулько, Ю. А. Классификация деловых писем в системе документооборота / Ю. А. Загорулько, И. С. Кононенко, Ю.В. Костов, Е. В. Сидорова; Международная конференция ИСТ’2003 «Информационные системы и технологии» – Новосибирск, 200 c.
6 Joachims T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. // Proceedings of ICML-97, 14th International Conference on Machine Learning. – 1996
7 Агеев, М. С. «Методы автоматической рубрикации текстов, основанные на машинном обучении знаниях экспертов» 2004 – 136 c.
8 Статья про спам и фишинг: официальный сайт URL:https://securelist.ru/spam-and-phishing-in-q2-2019/94529/ (дата обращения 10.04.2020)
9 Дюк, В. Data Mining: учебный курс. / В. Дюк, А. Самойленко – изд-во Питер, 2001.
