Введение
Кредитные операции – самая доходная статья банковского
бизнеса. За счет этого источника дохода формируется основная часть чистой прибыли,
отчисляемой в резервные фонды и идущей на выплату дивидендов акционерам банка.
Банки предоставляют кредиты различным юридическим и физическим лицам из
собственных и заемных ресурсов [1].
Для
организации кредитного процесса руководство банка принимает решение о
проводимой кредитной политике на конкретный период. В документе о кредитной
политике излагают основные направления кредитной работы, конкретные показатели
на предстоящий период.
Банки проводят
большую аналитику для разработки кредитных предложений, которые максимально
должны мотивировать клиента банка или нового пользователя взять кредит.
В настоящий момент, как
минимум в одном, а вероятно и во многих банках России и мира, составление и
подбор рекламных кампаний, предложение кредитных или иных услуг, тарифов
клиенту осуществляется за счёт строгой выборки по определённым критериям и
признакам, которые выделил банк у клиента. Такой подход достаточно хорош и
понятен. Но конкретно у одного банка России появилась заинтересованность в
рассмотрении более консервативного способа формирования групп клиентов. Смысл
в том, чтобы основанием вхождения в группу являлся не четкий перечень факторов,
а совокупность значений выбранных признаков. Для решения данной задачи был
выбран метод – кластеризация данных.
В связи с этим, актуальной
является задача разработки программного обеспечения, которое выполняло бы
кластеризацию выбранных данных, было удобно в использовании, предоставляло результаты
в пригодном для дальнейшей работы с ними виде.
Требования к функционалу
программного комплекса
К разрабатываемому
программному обеспечению предъявляется перечень требований. Программа должна
уметь считывать данные с файлов в форматах csv и txt. Для предоставления информации
о клиентах были выбраны именно эти форматы, так как файлы с такими расширениями
занимают меньше объема памяти относительно других текстовых форматов, с
которыми также можно работать в Office
Excel или подобных
программах, что удобно при работе с таблицами данных. Программное обеспечение
должно позволять обрабатывать информацию о клиенте, состоящую из 5 полей
(Идентификатор клиента, суммарное количество кредитов клиента, суммарное
количество просрочек, сумма всех кредитов клиентов, признак наличия отношения к
суду). Дополнительно, программа должна обеспечивать удобный и понятный вывод
информации о полученных кластерах, и объектах, входящих в них.
Реализация программного комплекса
Первая версия программного
обеспечения уже разработана и в настоящее время проходит этап тестирования на
контрольных примерах. Программа представляет из себя приложение для
операционной системы Windows, написанное на языке C# с использованием технологии Windows Forms [2].
В качестве алгоритма для
кластеризации был выбран алгоритм K–means
(K-средних). Этот алгоритм был выбран по нескольким
причинам [3]:
·
он достаточно прост в реализации;
·
его использование описано многими специалистами;
·
алгоритм не зависит от количества входных параметров объекта
кластеризации.
Выполним
описание сценария работы пользователя с разработанной программой. После запуска
программы пользователь видит окно настроек, необходимых для подготовки к
запуску кластеризации данных (рис.1.).

Рис.1. Стартовое окно программы – окно настроек кластеризации
В данном окне необходимо
указать путь к файлу с данными, подготовленными к кластеризации. Это можно
сделать либо вручную, либо нажав на кнопку «Обзор», и в открывшемся окне найти
нужный файл (рис.2.).
 Рис.2. Окно выбора файла с данными
Рис.2. Окно выбора файла с данными
На главном окне имеются
поле с названием используемого алгоритма кластеризации и поле выбора количества
кластеров (рис.3.).
Рис.3. Поле названия алгоритма
кластеризации и поле выбора количества кластеров
После выбора файла с
данными и заполнения количества кластеров, пользователь может приступать к
кластеризации данных. Для этого нужно нажать на кнопку «Старт».
Далее запускаются невидимые
для пользователя процессы – валидация входных данных, зачитывание объектов и их
кластеризация. Но пользователь может увидеть результат их работы. Процесс
валидации проверяет корректность введённого количества кластеров, заданы ли
путь к файлу и количество кластеров. Во время процесса чтения, могут возникнуть
непредвиденные ошибки, например, пользователь некорректно заполнил файл с
данными, или файл с данными уже открыт, и программа не может получить доступ на
чтение файла. Пользователь увидит информацию об этих ошибках благодаря
всплывающему окну (рис.4.).
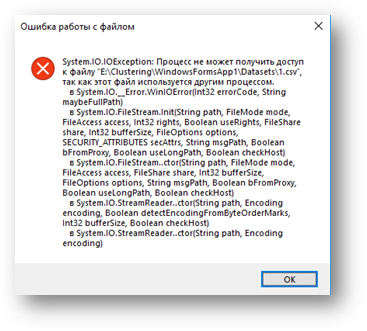
Рис.4. Окно с ошибкой
Если пользователь сделал
всё правильно, то результатом работы программы будут сформированные кластеры.
Количество элементов в каждом кластере можно будет увидеть в итоговом окне
(рис.5.). А состав кластеров будет представлен в виде файлов в формате csv, которые сохранятся в папке «Results»,
которая в свою очередь будет создана в том же месте, где располагается
исполняемый файл программы (рис.6.).

Рис.5. Окно с информацией о
количестве элементов в кластере

Рис.6. Папка с файлами кластеров
На рисунке 7 представлен
результат кластеризации на примере одного из полученных кластеров. Столбцы в
нём соответствуют столбцам исходного файла с данными.
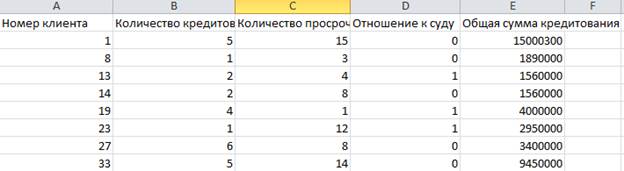
Рис.7. Результат кластеризации
Заключение
Таким образом, разработанный мною инструмент позволяет
закрыть потребность банка, инициатора данной разработки, в попытке более
консервативно сформировать новые группы клиентов, путём кластеризации данных о
них, для решения внутренних задач.
Литература
1. Кредитный риск и способы
его минимизации [Электронный ресурс] // Научная библиотека «Киберленинка». URL: https://cyberleninka.ru/article/n/kreditnyy–risk–i–sposoby–ego–minimizatsii/
(дата обращения 15.03.2020)
2. Windows Forms [Электронный ресурс] //
Документация Microsoft. URL: https://docs.microsoft.com/ru–ru/dotnet/framework/winforms/windows–forms–overview (дата
обращения: 16.03.2020)
3. Advantage & Disadvantages of k-Means and
Hierarchical Clustering (Unsupervised Learning) [Электронный
ресурс] // Martina Santini Computional Linguist, PhD. URL:
http://santini.se/teaching/ml/2016/Lect_10/10c_UnsupervisedMethods.pdf/ (дата обращения: 15.03.2020)
Литература на латинице (translit.ru)
1. Kreditnyj
risk i sposoby ego minimizacii [Jelektronnyj resurs] // Nauchnaja biblioteka
«Kiberleninka». URL:
https://cyberleninka.ru/article/n/kreditnyy-risk-i-sposoby-ego-minimizatsii/
(data obrashhenija 15.03.2020)
2. Windows
Forms [Jelektronnyj resurs] // Dokumentacija Microsoft. URL:
https://docs.microsoft.com/ru-ru/dotnet/framework/winforms/windows-forms-overview
(data obrashhenija: 16.03.2020)
3. Advantage
& Disadvantages of k-Means and Hierarchical Clustering (Unsupervised
Learning) [Jelektronnyj resurs] // Martina Santini Computional Linguist, PhD.
URL: http://santini.se/teaching/ml/2016/Lect_10/10c_UnsupervisedMethods.pdf/
(data obrashhenija: 15.03.2020)
